




一种基于双向门控神经网络的乌兹别克语词干提取方法
商品类型
专利
专利号
CN111241831A
所属行业
先进制造与自动化
归属方
新疆大学
上架日期
2020-07-14 23:17:49
交易方式
转让
交易价格
面议
详细介绍
[0001] 本发明涉及乌兹别克语词干提取方法领域,尤其涉及一种基于双向门控神经网络的乌兹别克语词干提取方法。
背景技术
[0002] 乌兹别克语作为形态复杂的黏着语,单词由词干和词缀组成,其中词干表达词义,而词缀只能黏附在词干表达语法范畴。词干提取(stemming)是针对文本中的单词进行词干词缀切分,从而获得词干的过程,是自然语言处理领域中的基础性研究内容之一,其提取结果直接影响信息检索、机器翻译等下游任务的性能。
[0003] 现阶段乌兹别克语的词干提取已有了初步的研究结果,基于规则和词典的方法是目前比较主流的研究方法。虽然基于规则和词典的方法准确率较高,但是完全依赖于先前构建的词干库和语言学家制定的语言规则。因此,受到词典和语言规则的限制,无法覆盖所有的词法规则,而且成本较高。黏着语形态的复杂性是由不同语法范畴的词缀相互组合所导致。随着规则的增多,逐渐会出现规则冲突问题。例如,在多义词或词干尾部包含与词缀相同的单词中,容易出现切分错误。因此,单独利用基于规则和词典的方法是很难满足大数据背景下的乌兹别克语词干提取任务。
[0004](一)发明目的
[0005] 为解决背景技术中存在的技术问题,本发明提出一种基于双向门控神经网络的乌兹别克语词干提取方法,避免人工制定语言规则和语言本身的二义性,用数据驱动的形式完成乌兹别克语词干提取任务。
[0006](二)技术方案
[0007] 为解决上述问题,本发明提出了一种基于双向门控神经网络的乌兹别克语词干提取方法,对现有Lovins算法进行改进,改进步骤包括:
[0008] S1:Lovins算法内增加去除前缀的步骤;
[0009] S2:保留Lovins算法中去除后缀的步骤;
[0010] S3:删除转换剩余部分的步骤;
[0011] 改进后的Lovins算法流程包括以下步骤:
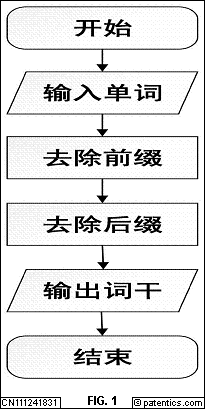
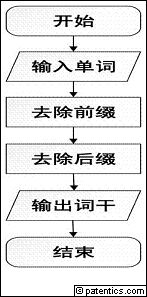
[0012] S11:开始;
[0013] S12:输入单词;
[0014] S13:去除前缀;
[0015] S14:去除后缀;
[0016] S15:输出词干;
[0017] S16:结束
[0018] 优选的,Lovins算法基于英文文本的词干提取算法,包括294种词尾、29种构词条件和35种转化规则。
[0019] 优选的,改进后的Lovins算法包括方法BiGRU,方法BiGRU包括成长短时记忆网络LSTM;成长短时记忆网络LSTM为在循环神经网络RNN的基础上增加了控制门和一个细胞状态,用于决定状态是否遗忘;控制门包括遗忘门、输入门和输出门。
[0020] 优选的,长短时记忆网络LSTM包括多个变体,其中一个变体为控循环单元网络GRU;控循环单元网络GRU包括两个控制门,分别为更新门和重置门。
[0021] 优选的,对改进后的Lovins算法训练步骤包括:S51:准备训练数据集;S52:数据数字化转换,准备输入数据;S53:利用BiGRU网络进行训练模型;S54:训练最优时保存模型;S55:利用已训练的方法对未标注的数据进性标注。
[0022] 本发明,避免人工制定语言规则和语言本身的二义性,用数据驱动的形式完成乌兹别克语词干提取任务。
[0023] 图1为本发明提出的基于双向门控神经网络的乌兹别克语词干提取方法的流程示意图。
[0024] 图2为本发明提出的基于双向门控神经网络的乌兹别克语词干提取方法中控循环单元网络GRU的结构示意图。
[0025] 为使本发明的目的、技术方案和优点更加清楚明了,下面结合具体实施方式并参照附图,对本发明进一步详细说明。应该理解,这些描述只是示例性的,而并非要限制本发明的范围。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本发明的概念。
[0026] 如图1-2所示,本发明提出的一种基于双向门控神经网络的乌兹别克语词干提取方法,对现有Lovins算法进行改进,改进步骤包括:
[0027] S1:Lovins算法内增加去除前缀的步骤;
[0028] S2:保留Lovins算法中去除后缀的步骤;
[0029] S3:删除转换剩余部分的步骤;
[0030] 改进后的Lovins算法流程包括以下步骤:
[0031] S11:开始;
[0032] S12:输入单词;
[0033] S13:去除前缀;
[0034] S14:去除后缀;
[0035] S15:输出词干;
[0036] S16:结束。
[0037] 本发明中,Lovins算法基于英文文本的词干提取算法,包括294种词尾、29种构词条件和35种转化规则,能够有效地处理英文单词中双写动词结尾和不规则单词的复数形式。
[0038] 由于乌兹别克语中存在较多的前缀,直接使用该算法会导致无法正确提取带有前缀的单词。因此,提出了基于改进的Lovins词干提取方法。改进算法中,首先增加了去除前缀的步骤;其次保留了去除后缀的步骤;最后由于乌兹别克语中,词干的形式是不会发生变化的,因此删除了转换剩余部分的步骤。
[0039] 在一个可选的实施例中,改进后的Lovins算法包括方法BiGRU,方法BiGRU包括成长短时记忆网络LSTM;
[0040] 成长短时记忆网络LSTM为在循环神经网络RNN的基础上增加了控制门和一个细胞状态,用于决定状态是否遗忘;控制门包括遗忘门、输入门和输出门。
[0041] 在一个可选的实施例中,长短时记忆网络LSTM包括多个变体,其中一个变体为控循环单元网络GRU;控循环单元网络GRU包括两个控制门,分别为更新门和重置门。
[0042] 控循环单元网络GRU是效果比较好而且网络结构更简单的网络变体。
[0043] 本申请给出了两种方法特征介绍,第一个方法简单只需要文本匹配的方法,根据已给定的词缀来切分单词进性词干提取,第二种方法是从给定的一切分的数据集里学习数据规律来训练成切分模型适用于后面的切分任务。第一种是规则驱动的方法,第二种是数据驱动的方法。
[0044] 下面是总的训练步骤:S51:准备训练数据集;S52:数据数字化转换,准备输入数据;S53:利用BiGRU网络进行训练模型;S54:训练最优时保存模型;S55:利用已训练的方法对未标注的数据进性标注。
[0045] 需要说明的是,构建词干提取数据集(数据集源于乌兹别克斯坦宪法,共包括7435个单词、568个句子,其中非重复单词1986个),分别构建了单词级数据集DATA-SET1和句子级数据集DATA-SET2;数据集DATA-SET1是由去重后的1986个单词组成、不存在句子,因此没有语境;而对数据集DATA-SET2没有做任何处理,该数据集中包含7435个单词和568个句子,具有一定范围内的上下文语境(滑动窗口大小为3,即考虑上一个词、当前词和下一个词)。
[0046] 实验数据采用交叉验证的方法获取训练集、测试集和验证集(切分比例为:0.8:0.1:0.1),实验数据统计如表1所示:
[0047] 
[0048] 表1:实验数据统计(单位:单词)
[0049] 不同模型和不同数据集的对比实验,分别在不同的数据集(DATA-SET1和DATA-SET2)上进行了Lovins算法和GRU网络的对比分析实验。实验数据统计如表2所示:
[0050] 
[0051] 表2:实验结果
[0052] 由上述比分析实验中可以发现:基于Lovins算法的词干提取模型提取结果明显低于其他两种方法。实验结果说明,基于规则的方法中使用规则库进行向前和向后匹配从而切分单词,由于语言规则无法覆盖所有的单词,规则之外的单词通常切分出错,因此采用基于规则的方法缺点较多,主要受限于规则库的规模以及规则之间的冲突。
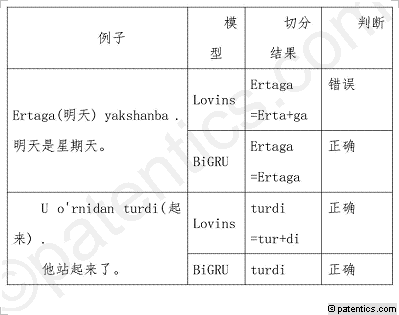
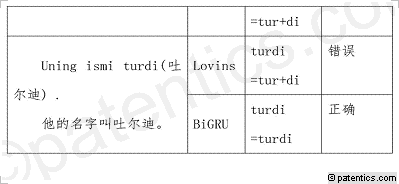
[0053] 表3为常见歧义现象:
[0054] 
[0055] 
[0056] 表3
[0057] 在表3中,列出了常见的歧义现象,当词干终部包含与词缀相同的字符时,例如“Ertaga(明天)”单词中(此单词中没有词缀),尾部出现了与向格词缀一样的字符串“ga”,如果使用基于规则的方法切分词干与词缀,会出现过度切分情况;当出现多义词时,例如“turdi(起来“动词”,吐尔迪“人名”)”中,如果不根据上下文语境来确定单词含义,会出现错误切分情况。由于语言歧义现象分布较离散,因此无法使用规则来进行映射。
[0058] 基于序列标注的词干提取模型中,使用BiGRU神经网络模型获得了最优的提取效果。因此,相比于以往基于规则的方法,将词干提取视为序列标注任务进行处理结果较好。
[0059] 数据集对比实验中可以发现:不同的数据集,对基于规则的方法没有明显的变化,但是对序列标注模型而言,效果有明显提升。可能的原因是DATA-SET2是句子级别的数据集,模型在训练过程中学习当前单词的上下文信息,有助于提高模型性能。
[0060] 此外,分析实验数据发现,主要的单词词缀源于名词且词缀类型比较相似。由于数据采集的领域单一,导致基于序列标注方法的实验结果表现较好。但随着数据集的增多以及领域的扩充,歧义单词会出现更多、规则库在数据集上的覆盖率更低。基于规则的方法性能可能会进一步降低。
[0061] 应当理解的是,本发明的上述具体实施方式仅仅用于示例性说明或解释本发明的原理,而不构成对本发明的限制。因此,在不偏离本发明的精神和范围的情况下所做的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。此外,本发明所附权利要求旨在涵盖落入所附权利要求范围和边界、或者这种范围和边界的等同形式内的全部变化和修改例。

